Adversarial Defenses
In progress
Usually, the parameters \(\theta\in\Theta\) of a deep neural network (DNN) \(f_\theta\) are trained by minimizing a loss \(\mathcal{L}\) on a training distribution \(\mathcal{D}\) as follows
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \mathcal{L}(f_\theta(x),y)\Big].\]However, as discussed in the previous blog post, the resulting trained DNN is vulnerable to adversarial attacks able to fool the DNN.
To mitigate the impact of adversarial examples, early works have suggested to train DNN on mixtures of clean and adverarial examples, thus leading to Adversarial Training techniques (see Section 1).
By elaborating on these heuristics, a theoretically grounded framework, called Adversarial Robust Training and based on robust optimization, has later emerged. There, a worst-case upper-bound of the objective, obtained by perturbing the data input \(x\) in order to maximize the original loss, is minimized. The resulting training procedure reads (see Section 2)
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \underset{\varepsilon\in\mathcal{S}}{\max} \mathcal{L}(f_\theta(x+\varepsilon),y)\Big].\]Now, if we let the family of distribution \(\mathcal{P}=\cup_{\varepsilon\in\mathcal{S}} P_\varepsilon\) where \(P_\varepsilon=\{ \{x+\varepsilon,y\}\colon \{x,y\}\sim\mathcal{D}\}\), then a weaker surrogate can be devised since
\[\underset{P\in\mathcal{P}}{\sup}\; \underset{(x,y)\sim P}{\mathbb{E}}[\mathcal{L}(f_\theta(x),y)] \leq \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \underset{\varepsilon\in\mathcal{S}}{\max} \mathcal{L}(f_\theta(x+\varepsilon),y)\Big].\]More generally, various distribution family \(\mathcal{P}\) could be used instead, thus leading to the class of Adversarial Distributionally Robust Training methods (see Section 3), i.e.,
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{P\in\mathcal{P}}{\sup}\; \underset{(x,y)\sim P}{\mathbb{E}}[\mathcal{L}(f_\theta(x),y)].\]Departing from these techniques, one could also consider noise-injection mechanisms (see Section 4) to induce smoothness, regularization techniques (see Section 5) and various other strategies (see Section 6).
1. Adversarial Training
The idea of adversarial training relies in also training the neural network model on adversarial examples in order to correctly predict their label.
Such type of techniques is also commonly called Adversarial Retraining in order to further contrast with the methods discussed in the next section.
AT [Szegedy et al., 2014] . This work first showed that by training a neural network \(f_\theta\) on a mixture of clean and adversarial examples, then \(f_\theta\) can be somewhat regularized. The corresponding training procedures amounts in solving
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \mathcal{L}(f_\theta(x),y) + \mathcal{L}( f_\theta(\varepsilon(x)),y) \Big]\]where \(\varepsilon(x)\) denotes an adversarial example crafted from \(x\).
AT-FGSM [Goodfellow et al., 2015] . The former idea was later popularized thanks to the efficient crafting of FGSM attacks. In addition, the authors considered a slighlty more general formulation by adding a weight parameter \(\alpha\in]0,1[\), i.e.,
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \alpha\mathcal{L}(f_\theta(x),y) + (1-\alpha)\mathcal{L}( f_\theta(\varepsilon^{\rm FGSM}(x)),y) \Big]\]AMT [Komiyama and Hattori, 2018] . Inspired by Generative Adversarial Networks (GANs), the Adversarial Minimax Training method uses two types of networks: a classifier \(f_\theta\) and a generator \(g_\nu\) trained to craft noise for adversarial examples. The overall optimization procedure seems to read
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{\nu\in\mathcal{V}}{\max}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \mathcal{L}(f_\theta(x),y) + \mathcal{L}( f_\theta(x+g_\nu(x)),y) \Big]\quad\text{s.t.}\quad g_\nu(x)\in\mathcal{B}\]where \(\mathcal{B}\) is a \(\ell_\infty\)-ball whose radius is weirdly estimated as well. While the idea is interesting it lacks some mathematical background. Note that the method is also closely related to the adversarially robust training techniques discussed in the next section.
RAT [Aurajo et al., 2020] . The Randomized Adversarial Training method combines both adversarial training and noise injection mechanisms.
2. Adversarial Robust Training
Robust Optimization is an area of optimization theory aiming to obtain solutions which are stable under some level of pertubation of the data. In the context of adversarial robustness, such perturbations are hence intended as adversarial perturbations. Formally, adversarially robust training can be framed as a min-max optimization problem as follows.
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \underset{\varepsilon\in\mathcal{S}}{\max} \mathcal{L}(f_\theta(x+\varepsilon),y)\Big]\]The inner maximization problem aims to find an adversarial perturbation of a given data point \(x\) that achieves a high loss while the goal of the outer minimization problem is to find model parameters so that the adversarial loss given by the inner attack problem is minimized.
This class of methods is commonly refered to as Adversarial Training. In that sense, the techniques reported in Section 1 can been seen as heuristics where the min-max problem is solved sequentially, i.e., adversarial examples are crafted by (approximatively) solving the inner maximization, and then the model parameters are optimized based on the generated adversarial examples.
RT [Shaham et al., 2018] . The Robust Training method suggested to replace the lower-objective by a surrogate obtained by linearizing the adversarial loss, i.e.,
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \underset{\varepsilon\in\mathcal{S}(x)}{\max} \mathcal{L}(f_\theta(x),y) + \langle \nabla \mathcal{L}(f_\theta(x),y),\varepsilon\rangle \Big]\]where \(\mathcal{S}(x)\) denotes the set of allowed perturbations added to the example \(x\).
LWA [Huang et al., 2016] . The Learning With an Adversary method considers the following peculiar setting
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \underset{\|\varepsilon\|\leq \delta}{\max} \mathcal{L}(f_\theta(x+\varepsilon),y)\Big]\]and explores two surrogate approximations of the lower-level problem. The first one relies on a linearization technique similar to RT while the second one considers the misclassification rate in place of the loss function.
ART [Madry et al., 2018] . This work first properly considered the optimization of the original Adversarial Robust Training saddle-point problem. As such, the authors have addressed each lower maximization by crafting PGD adversaries (see post on adversarial examples). In addition, they have shown that if a neural network is trained to be robust against PGD adversaries, then it will be robust against all first-order adversaries.
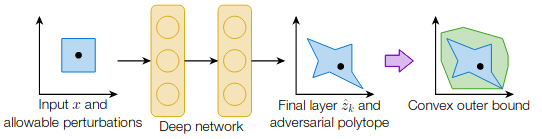
CAP [Wong and Kolter, 2018] . This work propose a method to learn deep ReLU-based classifiers that are provably robust against \(\ell_\infty\)-norm bounded adversarial perturbations. To do so, the authors consider a Convex outer relaxation of the Adversarial Polytope allowing them to incorporate the theory from convex robust optimization and provide provable bounds on the potential adversarial error and loss of the classifier. In addition, they provide an algorithm for certifying the robustness.
SDP SemiDefinite Program
3. Adversarial Distributionally Robust Training
Distributionally robust optimization seeks to robustify against unknown distribution shift explicitly. To do so, related methods usually begin by postulating a class \(\mathcal{P}\) of distributions around the data-generating distribution \(\mathcal{D}\), and then consider
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{P\in\mathcal{P}}{\sup}\; \underset{(x,y)\sim P}{\mathbb{E}}[\mathcal{L}(f_\theta(x),y)].\]WRM [Sinha et al., 2018] . The Wasserstein Robust Method considers a \(\rho\)-neighborhood of the distribution \(\mathcal{D}\) under the Wasserstein metric, i.e., \(\mathcal{P} = \{ P\colon W_c(P,\mathcal{D}) \leq \rho \}\). In addition, they consider a Lagrangian relaxation of the objective with fixed regularization parameter \(\lambda>0\), thus resulting in the following optimization problem.
\[\begin{align} &\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{P\in\mathcal{P}}{\sup}\; \left\{ \underset{(x,y)\sim P}{\mathbb{E}}[\mathcal{L}(f_\theta(x),y)] - \lambda W_c(P,\mathcal{D}) \right\}\\ \Leftrightarrow\quad &\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim \mathcal{D}}{\mathbb{E}}\Big[\phi_\lambda(\theta;\{x,y\})\Big] \end{align}\]with the robust majorant surrogate being the Moreau-Yosida regularization of the original loss, i.e.,
\[\phi_\lambda(\theta;\{x_0,y_0\}) = \underset{\{x,y\}}{\sup}\; \mathcal{L}(f_\theta(x),y) - \lambda c(\{x,y\},\{x_0,y_0\})\]where \(c\) denotes the transport cost. In particular, when \(c\) is the Euclidean distance, it boils down to the Pasch-Hausdorff envelope.
ARKS [Zhu et al., 2021] . The Adversarially Robust Kernel Smoothing method minimizes the following surrogate loss
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim \mathcal{D}}{\mathbb{E}}\Big[\ell^k(\theta;\{x,y\})\Big]\]where \(\ell^k(\theta;\{x,y\})\) is the \(k\)-transform of the original loss \(\ell(\theta,\{x,y\})=\mathcal{L}(f_\theta(x),y)\) obtained for some kernel \(k\), i.e.,
\[\ell^k(\theta;\{x_0,y_0\}) = \underset{\{x,y\}}{\sup}\; \ell(\theta,\{x,y\}) k(\{x,y\},\{x_0,y_0\}).\]One may view ARKS with Gaussian RBF kernel as the analog to WRM with type-2 Wasserstein distance, Laplacian kernel type-1 WRM, and \(c\)-exponential kernel general WRM with transport cost \(c\). The intuition of ARKS can also be viewed as using smooth kernels to model the distribution shift, then minimize the shifted risk.
4. Noise Injection Mechanisms
GDA [Zantedeschi et al., 2017] . The Gaussian Data Augmentation technique encourages the model to predict the same label for any input \(x\) and its slightly perturbed versions obtained by adding random Gaussian noise. To do so, the authors consider the following optimization problem
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{(x,y)\sim\mathcal{D}}{\mathbb{E}}\; \underset{\varepsilon\sim\mathcal{N}(0,\sigma^2)}{\mathbb{E}}\; \mathcal{L}(f_\theta(x+\varepsilon),y)\]where \(\sigma\) corresponds to the acceptable non-perceivable perturbation. In pratice, the expectation is replaced by \(N\) random noise instances.
RSE [Liu et al., 2018] . This paper introduces a defense algorithm called Random Self-Ensemble which adds a Gaussian noise layer before each convolution layer in both training and prediction phases. In practice, at inference time, RSE peforms \(K\) independent noisy forward pass, each yielding different prediction scores due to the noises, and then ensembles the results, i.e.,
\[\bar{f}_\theta(x) = \sum_{k=1}^{K} f_\theta^k(x)\]PNI [He et al., 2019] . The Parametric Noise Injection technique injects Gaussian noise to each component (e.g, input, weight, …) of the DNN. In addition, the variance of the noise can be tuned layer-wise through a coefficient whose authors suggest to additionnally estimate during the training of the network. An adversarially robust training optimization is also considered to improve the defense.
PixelDP [Lecuyer et al., 2019] . In this work, the authors proposed a randomization method by exploiting the link between differential privacy (DP) and adversarial robustness. Their framework inherits some theoretical results from the differential privacy community allowing them to evaluate the level of accuracy under attack of their method.
RS [Cohen et al., 2019] . The authors adopted the term of Randomized Smoothing to call adversarial defense techniques that transform any arbitrary base classifier into a new smoothed classifier that is certifiably robust in \(\ell_2\)-norm. As such, randomized smoothing was first proposed in PixelDP. Here, the authors tightened the analysis and complete the experiments.
StoBatch [Phan et al., 2020] .
5. Adversarial Robustness via Explicit Regularization
Let \(q_\theta(x,y)\) denotes the probability, predicted by the DNN \(f_\theta\), that \(x\) belongs to class \(y\). In most cases, \(f_\theta\) already outputs probabilities. If not, a soft-max operation can be added in the last layer. In addition, we restrict to the peculiar case where \(\mathcal{L}\) is the cross-entropy loss (note that in Pytorch, the cross-entropy function includes a soft-max operation). Thus, we have that
\[\underset{(x,y)\sim\mathcal{D}}{\mathbb{E}} \Big[ \mathcal{L}(f_\theta(x),y)\Big] = \underset{p(x,y)}{\mathbb{E}}\Big[ -\log q_\theta(y|x)\Big]\]TRADES [Zhang et al., 2019] . This work defined a new risk as the trade-off between natural and adversarial performances, controlled through an hyperparameter \(\lambda>0\). Formally, the defense problem reads
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{p(x,y)}{\mathbb{E}}\Big[ -\log q_\theta(y|x)\Big] + \lambda \underset{p(x)}{\mathbb{E}}\Big[ \underset{x^\prime\colon \|x^\prime-x\|p\leq \delta}{\max} \mathrm{KL}\left( q_\theta(\cdot|x) \| q_\theta(\cdot|x^\prime)\right)\Big]\]where the first term is the natural cross-entropy while the second term includes the Kullback-Leibler (KL) divergence between natural and adversarial probability distributions.
MART [Wang et al., 2020] . The Misclassification Aware adveRsarial Training method is a variant which hinges on boosted losses and whose regularizer treats differently the misclassified inputs.
MMA [Ding et al., 2020] . This methods intends to improve robustness by maximizing the average margin of the data distribution through a Max-Margin Adversarial training problem.
FIRE [Picot et al., 2021] . The authors propose a new formulation of adversarial defense with a FIsher-rao REgularizer. Here, the Fisher-Rao distance \(d_{R,\mathcal{C}}^2\) is used to capture the distance between probability distributions over the statistical manifold \(\mathcal{C} = \{q_\theta(\cdot|x)\colon x\in\mathcal{X}\}\) obtained by fixing the parameters of the DNN and changing its feature input in the manifold \(\mathcal{X}\). The resulting optimization problem reads
\[\underset{\theta\in\Theta}{\mathrm{minimize}}\; \underset{p(x,y)}{\mathbb{E}}\Big[ -\log q_\theta(y|x)\Big] + \lambda \underset{p(x,x^\prime)}{\mathbb{E}}\Big[ d_{R,\mathcal{C}}^2\left( q_\theta(\cdot|x),q_\theta(\cdot|x^\prime)\right)\Big]\]where \(\lambda>0\) controls the trade-off between natural accuracy and robustness to the adversary.
6. Other Defenses
Defensive Distillation [Papernot et al., 2016] . Distillation is a training procedure initially designed to train a DNN using knowledge transferred from a different DNN. The idea is to train two networks, namely the original network \(f_\theta\) and the distilled network \(f^{\rm d}_\nu\) with the same architecture. However, the distilled network is trained on the set \(\{x,f_\theta(x)\}\) where \(f_\theta(x)\) is used in place of \(y\). Such technique seems to prevent models from fitting too tightly to the data, and contributes to a better generalization around training point.
Randomization [Xie et al., 2017] . This heuristic defense technique works at inference time. Any input image go through two randomization layers. The first applies random resizing while the second applies random padding. Then, a single modified image is selected randomly before being fed to the classification network.
OPU [Capelli et al., 2021] . This defense expands the idea of obfuscated gradients to obfuscated parameters by physically implementing a fixed random projection followed by a non-linearity using an optical co-processor, where only the distribution of the random matrix entries is known and not their values. The defense is implemented by an analog layer through an Optical Processing Unit which multiplies any input vector by a fixed random matrix, using light scattering through a diffusive medium.
References
- [Aurajo et al., 2020] A. Araujo, L. Meunier, R. Pinot and B. Negrevergne. "Robust Neural Networks using Randomized Adversarial Training". ArXiv (2020)
- [Capelli et al., 2021] A. Cappelli, R. Ohana, J. Launay, L. Meunier, I. Poli and F. Krzakala. "Adversarial Robustness by Design through Analog Computing and Synthetic Gradients". ArXiv (2021)
- [Cohen et al., 2019] J. Cohen, E. Rosenfeld and Z. Kolter. "Certified Adversarial Robustness via Randomized Smoothing". Proceedings of the International Conference on Machine Learning (ICML) (2019)
- [Ding et al., 2020] G. W. Ding, Y. Sharma , K. Y.-C. Lui and R. Huang. "MMA Training - Direct Input Space Margin Maximization through Adversarial Training". International Conference on Learning Representations (ICLR) (2020)
- [Goodfellow et al., 2015] I. Goodfellow, J. Shlens and C. Szegedy. "Explaining and Harnessing Adversarial Examples". International Conference on Learning Representations (ICLR) (2015)
- [He et al., 2019] Z. He, A. S. Rakin and D. Fan. "Parametric Noise Injection - Trainable Randomness to Improve Deep Neural Network Robustness Against Adversarial Attack". Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
- [Huang et al., 2016] R. Huang, B. Xu, D. Schuurmans and C. Szepesvari. "Learning with a strong adversary". ArXiv (2016)
- [Komiyama and Hattori, 2018] R. Komiyama and M. Hattori. "Adversarial Minimax Training for Robustness Against Adversarial Examples". International Conference on Neural Information Processing (ICONIP) (2018)
- [Lecuyer et al., 2019] M. Lecuyer, V. Atlidakis, R. Geambasu, D. Hsu and S. Jan. "Certified Robustness to Adversarial Examples with Differential Privacy". IEEE Symposium on Security and Privacy (SP) (2019)
- [Liu et al., 2018] X. Liu, M. Cheng, H. Zhang and C.-J. Hsieh. "Towards Robust Neural Networks via Random Self-ensemble". Proceedings of the European Conference on Computer Vision (ECCV) (2018)
- [Madry et al., 2018] A. Madry, A. Makelov, L. Schmidt, D. Tsipras and A. Vladu. "Towards Deep Learning Models Resistant to Adversarial Attacks". International Conference on Learning Representations (ICLR) (2018)
- [Papernot et al., 2016] N. Papernot, P. McDaniel, X. Wu, S. Jha and A. Swami. "Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks". IEEE Symposium on Security and Privacy (SP) (2016)
- [Phan et al., 2020] H. Phan, M. T. Thai, H. Hu, R. Jin, S. Ruoming, T. Sun, and D. Dou. "Scalable Differential Privacy with Certified Robustness in Adversarial Learning". Proceedings of the International Conference on Machine Learning (ICML) (2020)
- [Picot et al., 2021] M. Picot, F. Messina, M. Boudiaf, F. Labeau, I. Ben Ayed and P. Piantanida. "Adversarial Robustness via Fisher-Rao Regularization". ArXiv (2021)
- [Shaham et al., 2018] U. Shaham, Y. Yamada and S. Negahban. "Understanding adversarial training - Increasing local stability of supervised models through robust optimization". Neurocomputing (2018)
- [Sinha et al., 2018] A. Sinha, H. Namkoong, R. Volpi and J. Duchi. "Certifying Some Distributional Robustness with Principled Adversarial Training". International Conference on Learning Representations (ICLR) (2018)
- [Szegedy et al., 2014] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow and R. Fergus. "Intriguing properties of neural networks". International Conference on Learning Representations (ICLR) (2014)
- [Wang et al., 2020] Y. Wang, D. Zou, J. Yi, J. Bailey, X. Ma, and Q. Gu. "Improving adversarial robustness requires revisiting misclassified examples". International Conference on Learning Representations (ICLR) (2020)
- [Wong and Kolter, 2018] E. Wong and Z. Kolter. "Provable Defenses against Adversarial Examples via the Convex Outer Adversarial Polytope". Proceedings of the International Conference on Machine Learning (ICML) (2018)
- [Xie et al., 2017] C. Xie, J. Wang, Z. Zhang, Z. Ren, and A. Yuille. "Mitigating Adversarial Effects Through Randomization". International Conference on Learning Representations (ICLR) (2017)
- [Zantedeschi et al., 2017] V. Zantedeschi, M.-I. Nicolae and A. Rawat. "Efficient Defenses Against Adversarial Attacks". Proceedings of the ACM Workshop on Artificial Intelligence and Security (2017)
- [Zhang et al., 2019] H. Zhang, Y. Yu, J. Jiao, E. Xing, L. Ghaoui and M. Jordan. "Theoretically Principled Trade-off between Robustness and Accuracy". Proceedings of the International Conference on Machine Learning (ICML) (2019)
- [Zhu et al., 2021] J.-J. Zhu, C. Kouridi, Y. Nemmour and B. Schölkopf. "Adversarially Robust Kernel Smoothing". ArXiv (2021)